Ce billet fait écho à la conférence que j’ai donnée le 15/09/2025 au Corum lors de l’Agile Tour Montpellier 2025 #atm25. Je remercie de nouveau chaleureusement les organisateurs de m’avoir donné cette opportunité ainsi que Akkodis, mon employeur, et Schneider Electric, le client chez qui je suis actuellement en mission, de m’avoir permis d’y prendre part.
Qu’est-ce qui nous amène là ?
En fait, tout part d’un constat simple et du questionnement qui en découle.
👉 Le constat
Scrum, en tant que framework volontairement incomplet, nous prévient en deux phrases des effets potentiellement positifs ou néfastes d’un Sprint trop long ou trop court… puis nous laisse seuls face au choix de sa durée. Et c’est logique : fidèle à ses racines empiriques, Scrum nous invite à découvrir par nous-mêmes la ou les durées de Sprint les plus adaptées à notre contexte et à nos enjeux.
🤔 Le questionnement
Sur le terrain, sur quoi basons-nous réellement la durée de nos Sprints ? Est-ce pour de « bonnes » raisons… ou au contraire pour des raisons peu adaptées à notre situation ? Et si ces raisons ne tenaient pas la route, pourrions-nous expérimenter autrement — et surtout, comment ?
C’est précisément ce que je vous propose d’explorer dans cet article, en croisant plusieurs perspectives complémentaires : Scrum (bien sûr), Kanban, le Flow, la Product Discovery et le Statistical Process Control.
C’est quoi le problème ?
Pour bien cerner le sujet, revenons à la source et posons une question toute simple :
👉 Qu’est-ce qu’un Sprint ?
En relisant le Scrum Guide — et surtout en lisant entre les lignes — on se rappelle qu’un Sprint est à la fois :
- un événement,
- un conteneur (« l’événement pour les contenir tous »),
- une cadence,
- une durée fixe (d’ailleurs, la durée maximale est bien de 1 mois, pas de 30 jours ni 4 semaines 👀),
- le cœur battant du framework,
- un projet de courte durée,
- une expérimentation,
- un cycle d’apprentissage,
- et, j’ajouterais : un pari.
Et un pari… ça se gagne ou ça se perd. Scrum nous invite justement à apprendre à en gagner le plus possible, tout en acceptant qu’il y aura forcément des pertes en route car nous n’innovons pas en faisant toujours la même chose, n’est-ce pas ?
Allons un cran plus loin :
👉 À quoi sert un Sprint ?
De nouveau, en relisant le Scrum Guide, entre ses lignes — et même en interprétant juste ce qu’il faut le texte — on comprend qu’un Sprint a plusieurs finalités essentielles :
- Mettre en œuvre les piliers empiriques de Scrum d’Inspection et Adaptation.
- Accroître la valeur et l’utilité du produit.
- Améliorer la prévisibilité dans l’apport de valeur et la réalisation du Product Goal.
- Contrôler les risques en termes de coût et d’effort.
- (In)valider les hypothèses sur le produit.
- Évaluer la validité du Sprint Goal, qui doit nous aider à…
- Nous rapprocher du Product Goal.
- Transformer une idée en un Incrément utile, additif, intégré et réellement utilisable (il y aurait beaucoup à dire ici 😄).
- Provoquer le changement, comme tout événement Scrum.
- Favoriser le focus et la cohérence, ce que l’on peut aussi interpréter à travers un prisme Kanban comme une forme de limitation du WIP.
- Maintenir un rythme durable.
Et donc… quelle durée de Sprint choisir ?
En croisant ce qui précède, on peut en déduire quelques implications importantes :
La durée du Sprint devrait apporter un équilibre entre focus sur l’objectif produit, apprentissage, et réactivité aux changements afin de limiter les risques économiques et humains, et de livrer régulièrement de la valeur à travers un ou plusieurs incréments.
Mais dans la pratique, mon expérience m’amène à constater que le choix de la durée des Sprints repose souvent sur des critères… disons, moins intentionnels :
- la capacité perçue : « En trois semaines, on aura le temps de bien finir les développements… »,
- l’habitude,
- le confort,
- des mythes et croyances personnelles : « Non, pas quatre semaines, sinon ce ne serait plus vraiment agile ! »,
- des effets de mode,
- une harmonisation forcée avec d’autres équipes,
- des pressions managériales,
- des contraintes de gestion de projet traditionnelles (CoPil, gates…),
- ou encore des difficultés organisationnelles et logistiques.
En d’autres mots : des critères très endogènes, où l’équipe regarde surtout vers l’intérieur, plutôt que vers la valeur, le flux ou l’apprentissage.
C’est grave, Docteur ?
Je dirais que nous avons au moins le devoir de faire mieux.
D’abord en nous plaçant dans la perspective du Scrum Master, qui — comme le rappelle le Scrum Guide — est « responsable de l’efficacité de l’équipe ». Mais aussi, et surtout… pour nos clients.
Efficacité, donc ? Nous utilisons ce mot en permanence. Mais savons-nous vraiment ce qu’il signifie ?
Puisque Scrum s’ancre dans le Lean (au passage, avez-vous remarqué que les mots « Agile » et « Agilité » n’apparaissent nulle part dans le Scrum Guide ? 👀), appuyons-nous sur une définition issue du Lean :
Efficacité : réaliser le bon travail, de manière durable et économique, pour apporter au client la bonne valeur, au bon moment, et ainsi l’aider à atteindre le résultat qu’il recherche.
Et c’est là que ça se gâte : nous vivons dans un monde « VUCA »…
VUCA ? Il s’agit d’un acronyme utilisé à l’origine par l’armée américaine pour décrire l’état du monde à la fin de la Guerre froide :
- V = Volatile
- U = Uncertain (incertain)
- C = Complex (complexe)
- A = Ambiguous (ambigu)
Mais en quoi cela nous concerne-t-il dans nos contextes de développement de produits ou de services ?
👉 D’abord, vis-à-vis de la « bonne valeur »
Comme l’affirment certains spécialistes de l’incertitude et de la complexité, la valeur client ne peut jamais être connue a priori — et encore moins « prouvée » a posteriori en cherchant à réduire le risque après-coup.
Mais tout n’est pas perdu, à condition de mettre l’apprentissage au cœur de notre démarche et d’écouter attentivement la Voice of the Customer (la voix du client). Et, bonne nouvelle : le Sprint est un cycle d’apprentissage et la Product Discovery est, par essence, centrée sur la voix du client.
👉 Ensuite, vis-à-vis du « bon travail » et du « bon moment »
Là encore, les experts de l’incertitude et de la complexité nous rappellent qu’en économie de la connaissance, prévoir les interactions et interférences entre composants d’un système est intrinsèquement incertain.
Vous vous souvenez peut-être de ce vieux slogan de la Banque Populaire ? :
« Additionner les talents. Multiplier les chances. »
Eh bien, dans nos contextes produits, ce serait plutôt :
« Additionner les composants. Multiplier les interactions et interférences… et donc les risques que ça ne se passe pas comme prévu 😅 »
Là encore, nous pouvons nous en sortir à condition de comprendre que la seule certitude est ce qui s’est déjà produit, que nos données sont un gisement de feedback, à condition de savoir les lire. Et pour cela, il ne suffit pas d’écouter la Voice of the Customer : il faut aussi prêter attention à une seconde voix tout aussi cruciale — la Voice of the Process (la voix du processus).
En mode découverte de notre « vrai » client
Quand vous lisez Voice of the Customer, vous pensez probablement à cette formule bien connue pour rédiger des User Stories (qui, soit dit en passant, ne font pas partie de Scrum mais viennent d’eXtreme Programming 🤓) :
« En tant que… J’ai besoin de… Afin de… »
Et vous avez raison. Mais voyons les choses en plus grand, en nous appuyant sur une définition qui s’inscrit à la croisée de la Product Discovery et du Statistical Process Control :
Voice of the Customer : ensemble des exigences, attentes et tolérances — exprimées ou observées chez le client — qui définissent ce qu’il considère comme apte à l’usage et justifient son investissement.
Ici, « usage » doit être compris au sens large : cela inclut son contexte, ses contraintes, son système, et surtout le résultat qu’il recherche. Quant à « l’investissement », il ne se limite pas à l’argent : il englobe aussi le temps, l’énergie intellectuelle, et même l’engagement émotionnel.
Si l’on adopte cette perspective pour déterminer la durée d’un Sprint, il devient logique de se baser sur des critères tournés vers l’extérieur, autrement dit, exogènes :
- le rythme auquel le client a besoin de recevoir de la valeur,
- le niveau de feedbackabilité des incréments par les parties prenantes (clients, utilisateurs, sponsors),
- la vitesse d’apprentissage attendue par ces parties prenantes,
- leur capacité d’assimilation des nouvelles fonctionnalités ou changements,
- l’utilisation réelle, mesurée, des incréments (grâce à l’instrumentation du produit — car « tout le monde ment », souvent sans le vouloir),
- l’écart de satisfaction client,
- la stabilité des besoins et demandes (la « maturité du marché »),
- la qualité de la relation avec les parties prenantes,
- leur disponibilité effective,
- la complexité réglementaire du domaine (développer une boutique en ligne n’est pas la même chose qu’une app bancaire ou un logiciel de robotique micro-chirurgicale),
- la fréquence des changements réglementaires ou des nouveautés concurrentes (la « pression environnementale »).
En résumé : ici, l’équipe regarde au-delà d’elle-même. Elle se positionne avec ses utilisateurs, ses parties prenantes et son environnement pour éclairer le choix de la durée des Sprints.
Pas de doute : l’ambition est ici beaucoup plus grande. Et si nous voulons réellement avancer dans cette direction, il nous faut des outils pour objectiver et soutenir notre apprentissage.
En nous concentrant sur certains des critères proposés ci-dessus, nous pouvons imaginer un petit jeu de métriques, en particulier des flow metrics orientées feedback, pour mieux écouter la Voice of the Customer.
👇 Voici, à titre d’exemple, 5 métriques utiles :
1. Nombre de jours entre la mise à disposition d’un incrément et la réception d’un feedback exploitable
↪ Répond à la question : « Nos parties prenantes répondent-elles assez vite ? »
2. Nombre de jours entre deux incréments ayant généré du feedback exploitable
↪ Répond à la question : « Créons-nous ensemble suffisamment d’occasions d’apprentissage ? »
3. Nombre de jours pour (in)valider une hypothèse
↪ Répond à la question : « Combien de temps nous faut-il pour transformer une hypothèse en connaissance exploitable ? »
4. Nombre absolu de parties prenantes impliquées (Sprint Reviews, sessions de Product Backlog refinement, etc.) sur une période donnée
↪ Répond à la question : « Combien de parties prenantes s’impliquent réellement dans nos interactions ? »
5. Nombre d’hypothèses (in)validées par période
↪ Répond à la question : « Quelle est la densité de notre apprentissage ? »
Ce qu’il faut noter à propose de ces métriques :
- Les 3 premières sont des temps d’écoulement (lead times ou cycle times), mesurés en jours calendaires — car les attentes et tolérances des utilisateurs ne s’arrêtent pas les week-ends, ni les jours fériés 😉.
- Les 2 dernières sont des débits, mesurés sur une période choisie (par exemple la durée du Sprint, mais pas nécessairement). L’essentiel est d’avoir assez de données sur la période pour éviter les effets de chunkiness (par exemple, lorsque passer de 4 à 5 hypothèses validées représente +25 %, alors qu’il ne s’agit que d’une seule unité supplémentaire).
Et en mode observation de notre processus de découverte
Nous voilà donc potentiellement outillés pour découvrir la Voice of the Customer. Reste à savoir maintenant si nous sommes réellement capables de manier cet outillage de manière profitable et durable. En effet, qui dit métriques, dit mesures répétées dans le temps et, dans une approche Lean, il n’est pas question de se faire violence une fois ou quelques fois, mais bien d’acquérir un nouveau geste régulier, indolore et bénéfique.
C’est pour ces raisons que nous allons désormais devoir écouter la Voice of the Process, c’est-à-dire celle de notre processus de découverte de la Voice of the Customer. Pour l’imager autrement : est-ce que notre processus de découverte nous crie des souffrances dans les oreilles, ou bien nous susurre une douce mélodie ?
Appuyons-nous ici encore sur une définition dans la lignée du Statistical Process Control et du Total Quality Management :
Voice of the Process : Schéma naturel de variation et de performance qu’un processus manifeste, tel que révélé par ses données dans le temps.
Variation, donc, que nous allons assurément retrouver dans nos mesures et nos métriques — les variations et la variabilité sont tout bonnement intrinsèques à la nature. Et là, vous serez sans doute tentés de recourir à des moyennes pour tenter de domestiquer toute cette « sauvagerie ».
✋ Oui… mais non… car — et cela va peut-être bouleverser votre vision du monde — une moyenne ne peut jamais (jamais [jamais]) être utilisée seule pour appréhender un phénomène variable, et encore moins pour prédire son comportement futur.
La prochaine fois que vous verrez une moyenne seule dans un PowerPoint, un reporting ou un burn-down chart… détournez le regard et éloignez-vous du piège des moyennes. Vous êtes en danger. En grave danger. Comme ce directeur commercial qui ne savait pas nager mais qui, voyant le panneau indiquant que l’étendue d’eau faisait en moyenne 90 cm de profondeur, s’est mis à la traverser… avant de se noyer. RIP.

Oui, car le cerveau humain est très (très) mauvais pour appréhender la variabilité à partir d’un simple tableau de valeurs.
Alors, que faire ?
Par chance, nous pouvons nous appuyer sur des outils de visualisation à la fois mathématiquement fiables et remarquablement simples à utiliser, issus du Statistical Process Control.
Run Chart
Le premier outil est ce qu’on appelle un Run Chart. C’est un outil basique, mais qui constitue une porte d’entrée idéale dans le monde fascinant de la variabilité. Malgré sa simplicité, il nous permet de commencer à observer les variations correctement et, le cas échéant, de détecter des tendances.
Souvenons-nous que notre objectif est d’évaluer la pertinence de la durée de Sprint que nous avons choisie (ou que nous expérimentons). Pour cela, nous nous sommes équipés de 5 métriques de flux orientées feedback.
Prenons ici la première : le nombre de jours entre la mise à disposition d’un incrément et la réception d’un feedback exploitable.
Au fil du temps, l’équipe va produire plusieurs incréments. Pour chacun d’eux, nous pourrons consigner :
- la date de mise à disposition de l’incrément,
- la date de réception du feedback exploitable,
- et en déduire le nombre de jours calendaires écoulés entre ces deux moments.
En bonus, nous pourrons aussi calculer la moyenne sur l’ensemble des incréments.
Facile, n’est-ce pas ?
Nous pourrons alors tracer le graphique correspondant dans notre tableur favori (Google Sheets, Microsoft Excel, Apple Numbers, LibreOffice Calc…) :
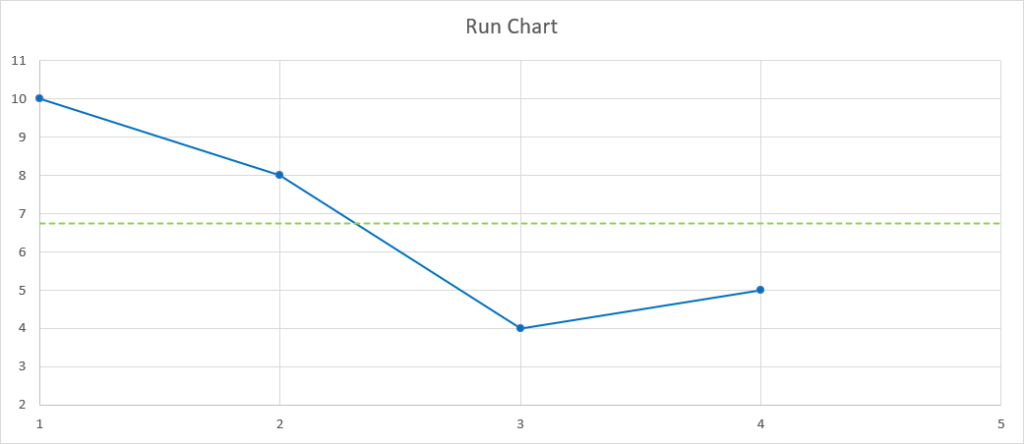
Que nous pouvons lire ainsi :
- Pour le 1ᵉ incrément, il s’est écoulé 10 jours avant de recueillir du feedback.
- Pour le 2ᵉ, 8 jours.
- Pour le 3ᵉ, 4 jours.
- Et pour le 4ᵉ, 5 jours.
Ces valeurs successives, représentées par la ligne bleue continue, fluctuent dans le temps autour de la ligne verte pointillée, qui correspond à leur moyenne, avec une amplitude facilement perceptible visuellement.
Vous serez peut-être tentés de vous dire :
« On dirait que nous nous sommes déjà nettement améliorés pour la récolte du feedback sur nos incréments. »
…et d’y voir une belle tendance à la baisse.
Si je vous dis que vous avez, grosso modo, 50 % de chances (une chance sur deux, donc) que la prochaine valeur soit au-dessus ou en dessous de la moyenne, est-ce que vous voyez les choses différemment ?
Illustrons cela en lançant une pièce en l’air :
- Pile → en dessous
- Face → au-dessus
…Face !

Pour notre 5ᵉ incrément, il nous a fallu 9 jours pour recevoir le feedback attendu. Adieu la belle tendance séduisante ! Mais ne vous y trompez pas, notre processus de récolte ne s’est pas « détérioré » : il est simplement en train de varier naturellement — il fluctue, oscille, comme tout processus « vivant ». Et aucune moyenne au monde ne peut révéler cela à elle seule (cf. flaw of averages).
En réalité, d’un point de vue mathématique et statistique, il faut au moins 8 points consécutifs qui vont dans la même direction pour pouvoir parler de tendance. Et c’est encore plus significatif si ces 8 points consécutifs traversent la ligne centrale (la moyenne) :
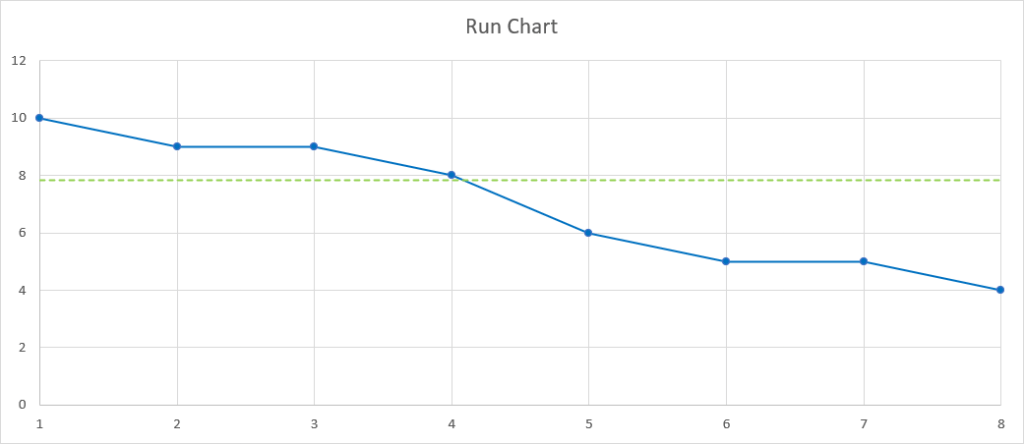
Pas mal pour un premier outil, non ?
Process Behavior Chart
Le second outil de visualisation à notre disposition est le Process Behavior Chart. On peut le voir comme le grand frère du Run Chart : une version « sous stéroïdes ». Pas parce qu’il serait compliqué à utiliser, bien au contraire : sa simplicité relative cache une puissance d’analyse exceptionnelle. Il nous permet notamment de détecter quand les variations de notre processus deviennent excessives.
👉 Avertissements
1. Il existe 7 types de Process Behavior Charts. Dans le cadre de cet article, nous nous concentrerons sur le XmR Chart, généralement le plus adapté aux contextes de développement de produits ou services.
2. Toute analyse de processus variable devrait virtuellement commencer par la construction d’un XmR Chart.
3. Ici, nous nous limiterons à la règle principale de détection offerte par un XmR, en laissant volontairement de côté les règles additionnelles, utiles pour détecter des signaux de moindre amplitude.
Alors, qu’est-ce qu’un XmR Chart ?
Un XmR Chart est composé de deux graphiques :
1. X Chart : trace les mesures brutes dans le temps.
2. mR Chart : trace les différences entre deux mesures successives, appelées amplitudes mobiles (moving Ranges = mR).
Ces deux graphiques sont indissociables et ne vont donc jamais l’un sans l’autre.
Bien, replaçons-nous dans notre exemple : nous nous intéressons à la première métrique, c’est-à-dire au nombre de jours entre la mise à disposition d’un incrément et la réception d’un feedback exploitable. Et imaginons que nous avons accumulé des mesures pour 8 premiers incréments, que nous avons tracées dans notre tableur favori :
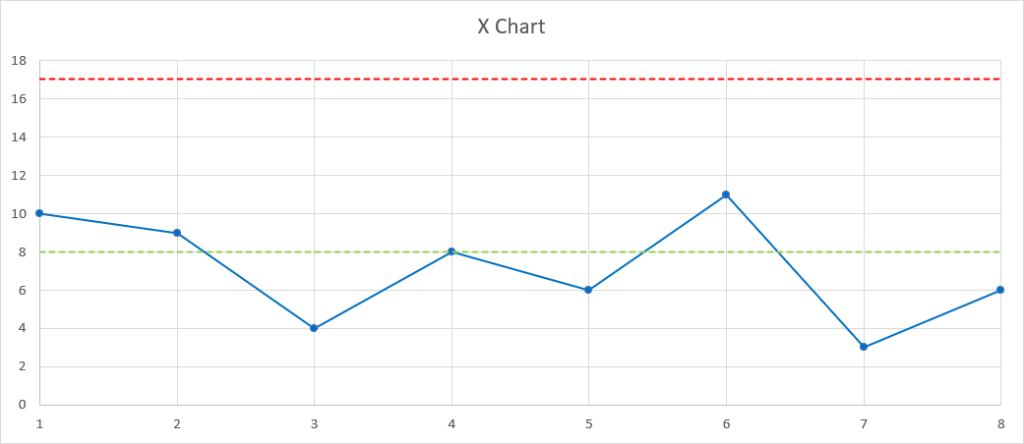
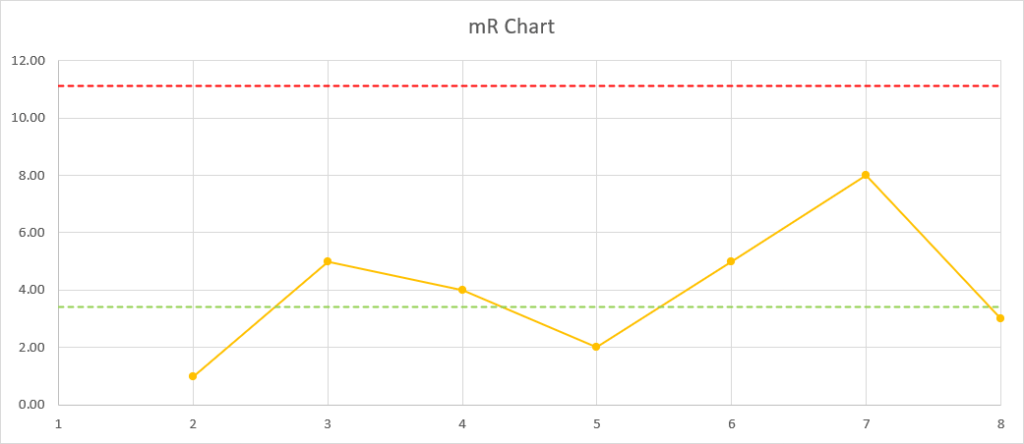
Vous pensez peut-être que ce graphique ressemble à deux Run Charts superposés… et vous avez raison.
Vous aurez également remarqué que chacun de ces deux « simili Run Charts » comporte chacun une ligne rouge pointillée :
- Sur le X Chart, cette ligne correspond à la limite haute naturelle du processus (upper natural process limit, UNPL).
- Sur le mR Chart, elle indique la limite haute d’amplitude (upper range limit, URL).
La raison d’être de ces deux limites est simple : elles nous signalent quand les variations de notre processus sont probablement devenues trop importantes.
Autrement dit, elles permettent de distinguer :
- les variations dues au hasard, aux causes communes (le « bruit » statistique) ; et
- celles causées par des événements spécifiques, des causes assignables ou spéciales (le « signal » statistique).
👉 Quelques points importants à propos de ces limites
- Toutes les mathématiques sophistiquées derrière ces calculs ont été initialement posées par le Dr. Walter Shewhart, puis affinées par les Drs. Edwards Deming, David Chambers et Donald Wheeler. Aujourd’hui, les résultats sont prêts à être utilisés facilement, sans prise de tête.
- Les calculs intègrent des facteurs de correction pour compenser le biais dans les mesures de dispersion (exemples: d₂ et D₄, ci-après).
- Les limites sont très conservatrices : elles sont conçues pour filtrer au moins 90 à 95 % du « bruit » statistique.
Concrètement : si toutes les variations restent sous ces deux limites sur la période observée, notre processus est très probablement stable, donc prévisible et « capable ». Quel formidable atout que de pouvoir le savoir empiriquement !
En pratique, les deux limites se calculent grâce à des formules simples qui ne nécessitent que des opérations arithmétiques de base (addition, multiplication, division), rien de plus :
👉 Pour le X Chart
UNPL = X̄ + E₂R̄ = X̄ + 3 mR̄/d₂
Où :
- X̄ = moyenne des mesures brutes
- mR̄ = moyenne des amplitudes entre deux mesures brutes consécutives ; et
- d₂ = 1,128.
👉 Et, pour le mR Chart
URL = D₄ mR̄
Où :
- mR̄ = moyenne des amplitudes entre deux mesures brutes consécutives ; et
- D₄ = 3,268.
Imaginons que nous ayons choisi d’expérimenter une durée de Sprint de 2 semaines, et que les XmR Charts de nos différentes métriques de découverte de la Voice of the Customer ne montrent que des variations communes, toutes contenues sous les limites hautes. À moins d’être pleinement satisfait de la « capabilité » de notre Voice of the Process — matérialisée par une faible hauteur des limites — cela peut être le signe qu’il est possible (et judicieux) de modifier notre système, ici en expérimentant une autre durée de Sprint.
Supposons donc que nous décidions d’expérimenter une durée de Sprint de 1 semaine.
Prenons de nouveau notre première métrique : le nombre de jours entre la mise à disposition d’un incrément et la réception d’un feedback exploitable. Après avoir remis nos compteurs à zéro, nous accumulons des mesures pour 12 incréments, que nous traçons comme précédemment dans notre tableur :


Et là… patatras ! Le 6ᵉ incrément dépasse l’UNPL sur le X Chart, et la 7ᵉ amplitude sur le mR Chart dépasse l’URL.
C’est un signal clair : il est impératif d’investiguer et de comprendre les causes spéciales qui ont probablemennt généré ces variations. Le cas échéant, nous devons ensuite apporter des remédiations afin que notre processus redevienne stable, prévisible et capable.
Si la remédiation est durablement efficace, formidable ! La Voice of the Process nous a permis de découvrir empiriquement une nouvelle durée de Sprint adaptée à notre Voice of the Customer. En revanche, si malgré plusieurs remédiations, notre processus continue de présenter des points au-dessus des limites, alors nous avons appris que ce système — cette durée de Sprint — ne fonctionne pas pour notre Voice of the Customer, et rend le processus instable et imprévisible.
L’intuition, c’est bien. Avec des faits, c’est encore bien mieux, non ?
Au fait, combien d’échantillons ?
Nous l’avons évoqué implicitement jusqu’ici, rendons-le maintenant explicite.
👉 Run Chart
Il faut disposer d’au moins 8 points de données, pour se mettre en position de détecter une éventuelle tendance.
👉 XmR Chart
Il faut entre 8 et 12 points pour calculer les limites naturelles (UNPL et URL). Avec 8 points, les limites risquent d’être « gonflées » — c’est-à-dire placées artificiellement trop haut. À partir de 12 points, elles commencent à converger, et leur précision devient vraiment optimale autour de 20 à 25 points.
8 points, 12 points : cela peut paraître beaucoup… mais l’alternative serait de continuer à errer dans le brouillard, sans comprendre le comportement réel de notre processus.
⏳ L’attente en vaut sans doute bien la peine.
Si je nous résume…
Si vous avez eu le courage de lire cet article jusque-là, vous aurez alors vu que :
- Le choix de la durée de Sprint devrait se faire en connaissance de cause, et non de manière arbitraire.
- Nous devons viser l’efficacité pour nos clients.
- Mais nous évoluons dans un monde VUCA.
- Pour y faire face, il est crucial d’écouter la Voice of the Customer.
- Nous pouvons la découvrir en nous outillant, par exemple avec des Flow Metrics orientées feedback.
- Il faut toujours éviter le piège des moyennes (flaw of averages).
- Et pour mieux comprendre notre fonctionnement, il est aussi essentiel d’écouter la Voice of the Process.
- Celle-ci se révèle empiriquement, au minimum grâce à de simples Run Charts, et au mieux via les puissants XmR Charts.
Ah… One more thing
Notre Voice of the Customer et notre Voice of the Process sont particulièrement utiles — voire nécessaires — pour vérifier empiriquement si la durée de Sprint choisie est adaptée.
Mais, à l’inverse : nous n’avons pas forcément besoin de Sprints pour faire ce travail. Nous pouvons tout à fait découvrir la Voice of the Customer, analyser la Voice of the Process et améliorer notre efficacité dans un contexte sans timebox, comme celui offert par Kanban, Lean ou Lean UX.
Elle est pas belle, la vie ? 😄
